The Spark Selects series features a monthly article from one of our team members.
To nurture creativity in Spark, we encourage our employees to discuss their desired topics and interests. The views expressed here are strictly those of the writers and not of Spark. If you are interested in our B2B content, head on over to our Spark's Voice Blog, and if you are a startup founder looking for some inspirational and educational reading, check out our Startup Series.
It’s early evening. You’re enjoying the warmth of a cup of tea and the sky is getting darker. From your window, flashes of a red coat against the grey street tell you little Kay from next door is playing outside. You start thinking about what to do for dinner. DING! Ah, someone’s at the door! Who can it be? You’re not expecting a package. Is Kay pranking you again
Without realising it, you just have used a predictive model. You haven’t confirmed that someone is at the door yet. You just guessed it from the doorbell ring.
A model is a partial, limited representation of the world.
A predictive model is a model that allows, from known data, to estimate data not yet known or not directly accessible.
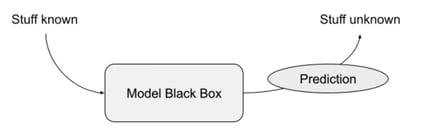
This becomes our Doorbell example case:
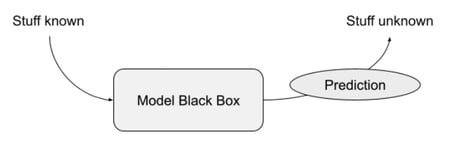
Now that we have formalised the General Doorbell Model, we can build on it. Namely, to answer the pending question: Who is at the door?
The data unknown is your visitor. The data known is; general knowledge about people who can show up on a doorstep, your context knowledge (time, day, weather, no package expected…) and your understanding of who has visited you before.
Now is the tricky model creation part. With context, what are the logical connections between the current unknown visitor and the past-known visitors?
The choice of a model starts by understanding its limits. We already have constraints from the data provided. A doorbell ringing can be described as an event. Event predictions have an entire branch in maths: statistics. Therefore there are still plenty of possible models.
I’m very tempted to do a “That’s all folks!” and leave it for the day. Choosing between those models is a full article by itself. For now, I will simplify the problem to get some simple predictions. These will be rough, unproven simplifications. Replicate this at home with utmost caution!
We want to guess your visitor in particular so let’s forget general knowledge and concentrate on your experience;
- I will assume that the visitor type doesn’t depend on the context (meaning the model doesn’t forbid the postman to pass on Sunday 3 am).
- The current visitor has already visited in the past with the same frequency (This means the recent visitor is the same as a random visitor in the past).
- The visitor can be a person (little Kay) or a role (the postman), and I will categorise as I see fit from the past data.
Here is the list of visitors that have rung your bell in the fictional house you reside in, over the past six months.
Movers, Alice (neighbour), Bob (neighbour), Package delivery, Package, Internet people, Bob, Package, Charlie (neighbour), Dee (friend), Package, Postman, Dee, Group of friends, Postman, No one, Group of friends, Postman, Group of friends, Bob, Census people, Dee, Postman, Postman, Kay (neighbour), Kay, Plumber, Kay, Kay, Kay, Dee, Postman, Package, Kay, Group of a friend, Kay, Kay, Jehovah witness, Kay, Dee, Alice, Kay, Kay, Package, Kay, Dee.
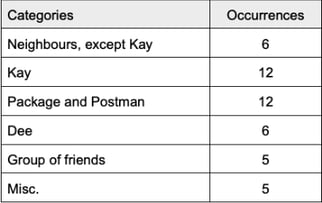
Categories and their number of occurrences, grouped in a manner to avoid 1 occurrence category and singling out the most frequent callers:
When those numbers are divided by the total number of occurrences, they give the probability that a random past visitor belongs to that category. With the model assumptions, that probability is the same as the probability of our current visitor belonging to that category.
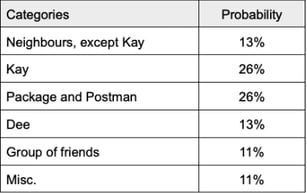
With a 50–50 chance, our surprise caller is either Kay or a package/post-delivery.
This is quite a simple example, but it shows a classic Data Scientist thought process. Let’s break it down.
- Think about the problem and develop a first common-sense model (“The General Doorbell Model”).
- Discard the model because of accuracy constraints. (We want to know who’s at the door).
- Check literature for existing models and inspiration. (Not a literature check per se here, just some general knowledge about statistics).
- Create a new model which needs data for calibration/training. (The combination of basic statistics and my 4 assumptions for simplification).
- Get the data. (Blessed be your perfect fictional memory! Getting the data is usually somewhere between difficult and impossible).
- Examine and clean your data. (Here only categorisation).
- Note that when you start with the data, the examination is usually done before the model choice and sometimes even before the problem definition to help with the assumptions.
- Calibrate and train the model from the data. (Here, we use high maths, known as addition by category and division by total).
- Save the model somewhere next time you want to use it (Crucial!)
And Voila! A fictional doorbell event model based on Data Science.
Could you think of other daily-based model examples? Let us know.
While you’re still here, do you want to see how Spark can help you understand data and create value-added impact? Speak with our experts today and see what we can do for you!🚀

